A continuación hablaremos de los estándares ASCII y UTF-8, los dos estándares de codificación de caracteres más populares y a su vez los más importantes, siendo ASCII el estándar pionero y UTF-8 el estándar que hoy en día domina la informática y las redes.
La codificación de caracteres
Toda la información digital se almacena de manera binaria, es decir, secuencias interminables de ceros y unos denominados como bits. A su vez, la misma se divide en distintas unidades que separan a dichos bits en grupos, siendo la más pequeña de estas el byte, el cual por regla general agrupa a 8 bits denominados popularmente como el octeto.
Nota: existen otras unidades más pequeñas como el nibble, que agrupa 4 bits, pero su uso es mínimo y solo sirven para operaciones muy específicas.
0000011010101101100010100011 representa 4 bytes de información. Es decir, si lo dividimos en cuatro partes obtendremos 4 bytes de ocho bits cada uno y esto será una porción de información. El problema es que los seres humanos no somos buenos para leer cadenas numéricas tan largas, nosotros, desde los tiempos de los egipcios e incluso mucho antes, nos manejamos con sistemas de escritura y alfabetos.
Es aquí donde entran en juego los estándares de codificación de caracteres, o sistemas de caracteres o charsets ya que estos traducirán, dependiendo del estándar en el que se basen, las combinaciones de bits dentro de dichos bytes a letras, números o signos de puntuación, etc. haciéndolos así fáciles de entender para los seres humanos
Estándares de codificación de caracteres: estos estándares son básicamente una manera de convertir información binaria en caracteres de un alfabeto o silabario, números y signos de puntuación. En sí estos son sistemas de representación regulados que permiten convertir o «traducir» información binaria en caracteres legibles. Por ejemplo, en el caso de ASCII, permitirá convertir distintas secuencias binarias a los caracteres de la lengua inglesa.
ASCII
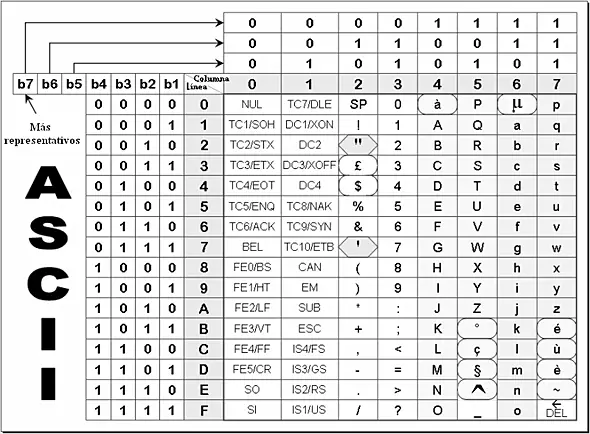
ASCII, por sus siglas en inglés Código Estándar Estadounidense para el Intercambio de Información (American Standard Code for Information Interchange), es un estándar de codificación de caracteres que convierte o «traduce» un byte en una letra, número o signo de puntuación a partir de la secuencia de ceros y unos que contenga el byte en cuestión.
Este es uno de los sistemas más antiguos, y a su vez más limitados, ya que fue pensado enteramente para la lengua inglesa. Razón por la cual en el mismo no existen caracteres acentuados o letras que no existan en el inglés como la ñ.
Nota: los sistemas de representación son muy importantes en la informática ya que todo es estandarizado y representado o encodificado en distintos sistemas. Por ejemplo, la información que forma los gráficos de un computador se representa en píxeles o vectores.
El mismo esta ligado al octeto de bits (ceros y unos) que conforman a un byte. Un bit es reservado para la paridad (la cual se utiliza para determinar si hubo errores de transmisión) y los siete bits restantes para formar el valor del caracter. Razón por la cual el sistema ASCII pueden representar 128 valores que van del 0 al 127 (las 128 combinaciones que se pueden lograr combinando los siete ceros y unos del byte en cuestión descontando el bit de paridad).
- 0000000
- 0000001
- 0000010
- 0000011
- etc.
Esto representa una gran limitación ya que sólo se pueden obtener 127 combinaciones, Por esta razón en el estándar ASCII solo encontraremos lo siguiente:
- Letras del alfabeto inglés minúsculas
- Letras del alfabeto inglés mayúsculas
- Signos de puntuación básicos
- Algunos caracteres de control
- Antiguamente los caracteres de control se utilizaban en las terminales de texto para enviarle ciertas órdenes a la terminal, como por ejemplo, hacer un beep o enviar la información.
ASCII extendido
Debido a las limitaciones del estándar original, es que se define el ASCII extendido en el cual el octavo bit del octeto, el cual en el ASCII original se utilizaba para operaciones de paridad, se reordena para también formar parte del valor del carácter a definir, dándole así la posibilidad al ASCII extendido de representar 256 caracteres.
UTF-8 y Unicode
UTF-8 es parte del estándar denominado como Unicode o UCS (Universal Coded Character Set) una solución estandarizada en el año 1991 con el fin de crear un sistema codificación de caracteres internacional que cubra a todas las lenguas de la humanidad más una infinidad de símbolos y signos extra.
En total Unicode define a unos más de 50 mil caracteres, símbolos y signos de todas las culturas humanas incluidos varios símbolos técnicos, lingüísticos, culturales y de ingeniería. Con la posibilidad de agregar cientos de miles más en el futuro si es necesario.
UTF-8
UTF-8 es parte del estándar Unicode y significa «8-bit Unicode Transformation Format». La principal característica del mismo es que posee un tamaño variable, que puede ser representado desde 1 a 4 bytes, por lo que es capaz de representar 1.112.064 caracteres. UTF-8 fue introducido en el año 1992 como parte del estándar Unicode.
UTF-8 fue diseñado por Ken Thompson y Rob Pike, y es compatible con ASCII (es decir, información codificada en ASCII puede funcionar perfectamente con Unicode ya que Unicode fue diseñado para que su primer byte concuerde con ASCII). UTF-8 es el sistema de codificación más popular hoy en día en la Internet y la absoluta mayoría de las bases de datos en el mundo.
Unicode y UTF-8: debemos tener en cuenta que Unicode simplemente define una gigantesca tabla de caracteres a los cuales les asigna un código o valor, mientras que los estándares de la familia Unicode, como el UTF-8 se las ingenian para codificar esos caracteres respetando los códigos de la tabla.
Estructura de los caracteres UTF-8
Además de todo lo mencionado anteriormente una de sus mayores ventajas es la inclusión de sincronía, es decir, gracias a esto se puede determinar el inicio de cada uno de los caracteres sin tener que reiniciar desde el principio de la transmisión del mensaje con cada lectura de carácter. Por último, UTF-8 no superposiciona valores, los conjuntos de valores que toma cada cada byte de un carácter son disjuntos, por lo que no se confunden entre si.

La imagen anterior nos ayuda a entender la estructura de un carácter UTF-8. Los caracteres Unicode se dividen en distintos grupos (funcionales a la cantidad de bytes necesarios para codificalos). Por ende, la cantidad de bytes necesarios es dependiente del código de carácter que Unicode ha asignado (ver la lista a continuación).
Inicio de cada carácter UTF-8
Los bits de mayor significación del primer byte de un carácter multi-byte determinan la longitud de la secuencia (110 para dos bytes; 1110 para tres bytes, 11110 para 4 bytes). Gracias a estos bits significantes se puede determinar el inicio de cada caracter y realizar la sincronía.
Tipos de caracteres UTF-8
- Caracteres de un byte: equivalen a los caracters ASCII.
- Caracteres de dos bytes: son 1920 caracteres que incluyen los caracteres de las lenguas europeas y arábigas.
- Caracteres de tres bytes: incluye los caracteres de las lenguas asiáticas y los plano básico multilingüe de Unicode.
- Caracteres de cuatro bytes: símbolos matemáticos, alfabetos clásicos, caracteres académicos y culturales así como caracteres del alfabeto persa y fenicio entre varios otros.
Más sobre informática
― RAD6000, el ordenador de 33 MHz que cuesta 300 mil dólares
― Los ordenadores caseros. Computadores construidos desde cero